云服务器搭建hadoop集群思路与报错整理
云服务器搭建hadoop集群思路与报错整理
我的版本:hadoop:3.2.3 jdk: 11 centOS:7.6
建议在配置之前全部打一个快照方便出错搞混或者解决不了时回滚!为了避免后续启动集群各种各样连接超时,连接错误,禁止访问等问题,需在云服务器商提供的控制台开放所有端口。
大纲
创建hadoop用户与程序准备
创建hadoop用户与主机名配置
我将使用三台云服务器搭建一个一主两从的服务器集群,搭建前先使用xshell或者其他连接工具连接上三台云服务器,选定一台配置较高的服务器当做主服务器(Master),(Master:2核4G,Slave1: 1核2G,Slave2:1核2G)。先配置Master在配置其他两台从机。
租服务器时不做设置登录上都是root用户,在xshell上执行命令
1 | useradd -m hadoop -s /bin/bash # 创建新用户hadoop |
修改hadoop用户密码,两遍确认
1 | passwd hadoop |
为hadoop用户增加管理员权限
1 | visudo |
编辑页面按下:100然后按下i在root那一行下添加一行hadoop ALL=(ALL) ALL

esc然后:wq保存
在每一台机器创建hadoop用户
配置主机名
为了后续搭建集群和配置更简单直观,改一下主机名,并配置hosts文件。云服务器集群和虚拟机集群的hosts配置有所不同
1 | vim /etc/hostname # 修改主机名 |

**注:**主服务器改为Master,其他两台为Slave1和Slave2并且不能有空格
配置hosts文件
1 | vim /etc/hosts # 注意每台机器的hosts都不一样 |
Master的hosts文件追加
1 | 内网ip Master Master |
内网ip可以通过ifconfig查看(如下192.168.0.4),外网ip即连接xshell的ip
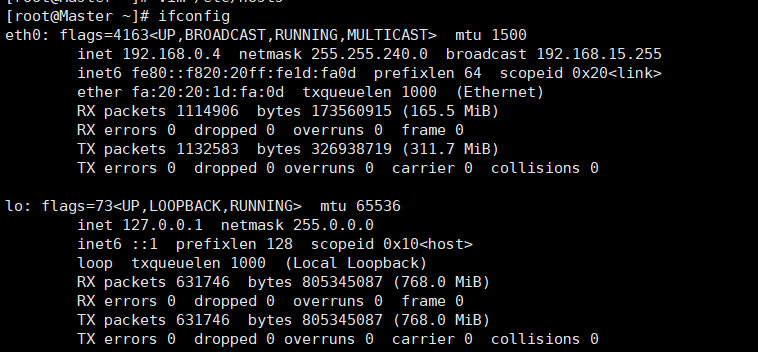
不能出现127.0.0.1 Master这样的记录
Slave1上
1 | 内网ip Slave1 Slave1 |
其他从机同理
重启三台云服务器
重启后即可用xshell连接每台的hadoop用户
在每台机器上ping其他节点看是否成功
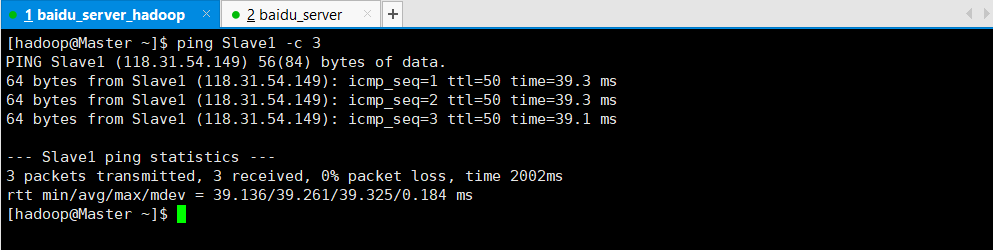
没ping通再检查一边配置或者重新配置。
配置ssh免密登录
之后的操作默认都在hadoop用户下操作。
CentOS默认安装有SSH使用命令查看
1 | rpm -qa | grep ssh |

未安装执行:
1 | sudo yum install openssh-clients |
执行命令测试
1 | ssh localhost # 如果可以登录 使用exit退出 |
在Master节点生成公钥
1 | cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost |
让Master无密码ssh本机
1 | cat ./id_rsa.pub >> ./authorized_keys # 执行后使用 ssh Master 验证 |
分发公钥给所有从节点
1 | scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/ # 其他从节点同理 |
在从节点上将ssh公钥授权(Slave1为例)
1 | mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略 |
在Master上测试
1 | ssh Slave1 |
如果还是连不上,在每台从机上执行如下操作
2
3
4
chmod 700 ../
chmod 700 .
chmod 600 authorized_keys

xsync文件分发脚本(尚硅谷)
1 | cd ~/bin # 如果提示找不到路径 先执行mkdir ~/bin再执行cd 命令 |
1 | !/bin/bash |
保存退出
添加环境变量
1 | chmod 777 xsync # 增加文件可执行权限 |
如果想在root用户或者其他用户下也能使用,其他环境变量同理
2
source /etc/profile
验证
1 | cd ~ |
如果提示错误信息:
rsync common not found执行如下操作:
安装jdk
下载地址:oracle
在Master上
1 | cd /usr/local |
下载完成通过把xftp或者其他工具上传压缩包到devtools目录
解压:
1 | sudo tar -zvxf jdk-11.0.15.1_linux_bin.tar.gz |
添加环境变量(开发环境最好加到全局环境变量里面,所有用户都能使用)
1 | sudo vim /etc/profile # 增加如下环境变量 |
分发给所有节点
1 | cd /usr/local |
在所有从节点上配置JAVA环境变量并验证
安装hadoop
下载地址:镜像站
Master上,上传压缩包到/usr/local目录
1 | cd /sur/local |
分发:
1 | cd /usr/local |
集群配置
集群部署参考尚硅谷hadoop教程,如下:
| Master | Slave1 | Slave2 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager JobHistoryServer |
NodeManager |
| SPARK | Worker HistoryServer |
Worker | Worker |
配置文件
在Master上:
workers
1 | vim /usr/local/hadoop/etc/hadoop/workers # 添加内容如下 |

core-site.xml
1 | cd /usr/local/hadoop/etc/hadoop |
在<configuration></configuration>中添加:
1 | <!-- 指定HDFS中NameNode的地址 --> |
hdfs-site.xml
1 | cd /usr/local/hadoop/etc/hadoop |
1 | vim hdfs-site.xml # 添加如下 |
1 | <!-- 指定NameNode的webui端口 --> |
yarn-site.xml
1 | cd /usr/local/hadoop/etc/hadoop |
1 | vim yarn-site.xml # 添加如下 |
1 | <!-- Reducer获取数据的方式 --> |
mapred-site.xml
1 | cd /usr/local/hadoop/etc/hadoop |
1 | vim mapred-site-xml # 添加如下 |
1 | <!-- 指定MR运行在Yarn上 --> |
分发配置文件
1 | cd /usr/local/hadoop/etc |
集群启动
关闭每台服务器的防火墙:
1 | sudo systemctl stop firewalld # 临时关闭防火墙 |
在Master上:
1 | cd /usr/local/hadoop |

**注:**因为我后续配置了Spark历史服务器的原因所以有HistoryServer进程
在Slave1上:
1 | cd /usr/local/hadoop |
如果报错permission denied 需要在Slave1上配置Master和Slave2的ssh登录,即在Slave1上生成公钥再在Master和Slave2上给公钥授权

**注:**因为我后续配置了yarn历史服务器的原因所以有JobHistoryServer进程
在Slave2上:
1 | jps # 查看hadoop进程 |

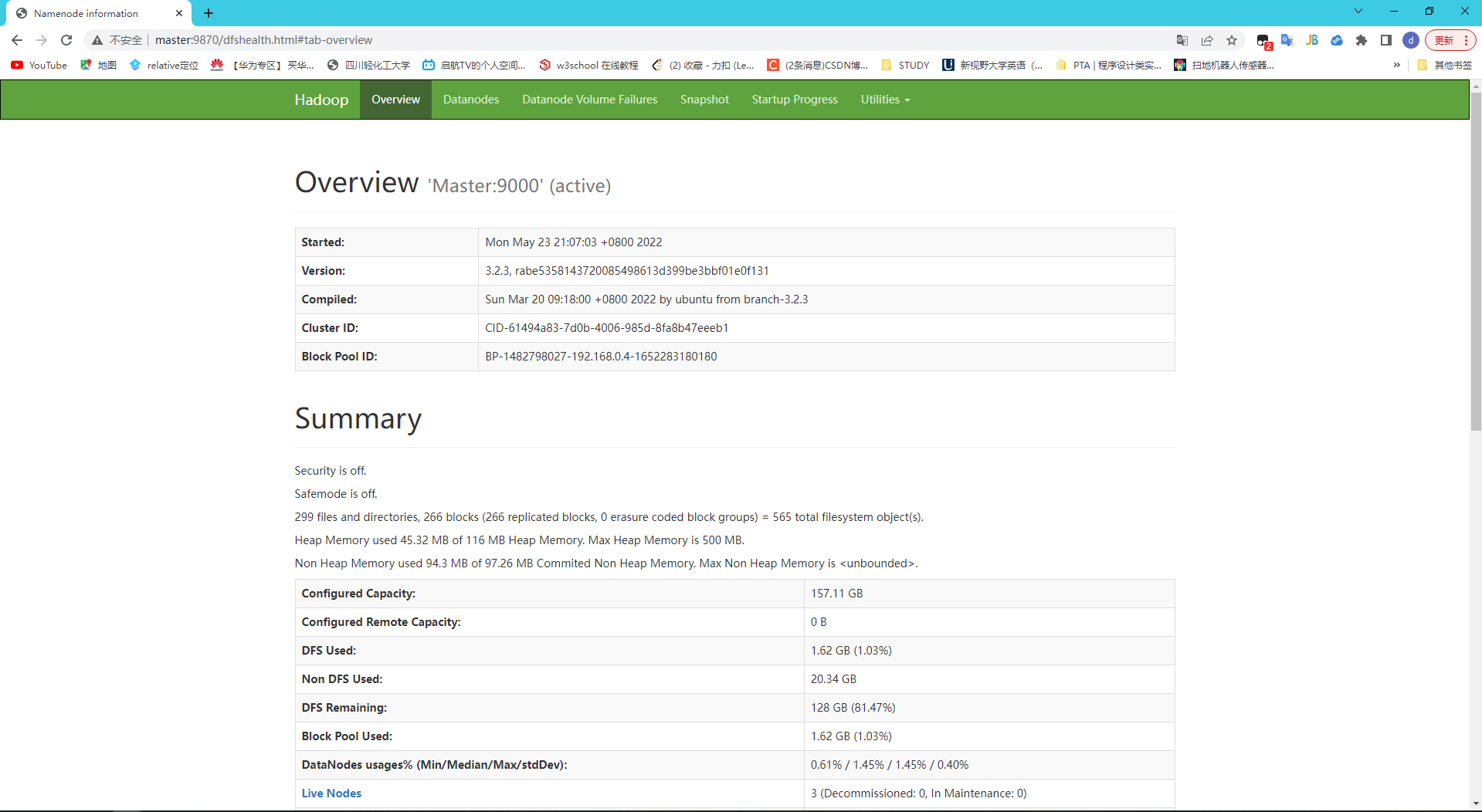
服务器进程开启情况和预期部署规划一致,证明没有什么问题。
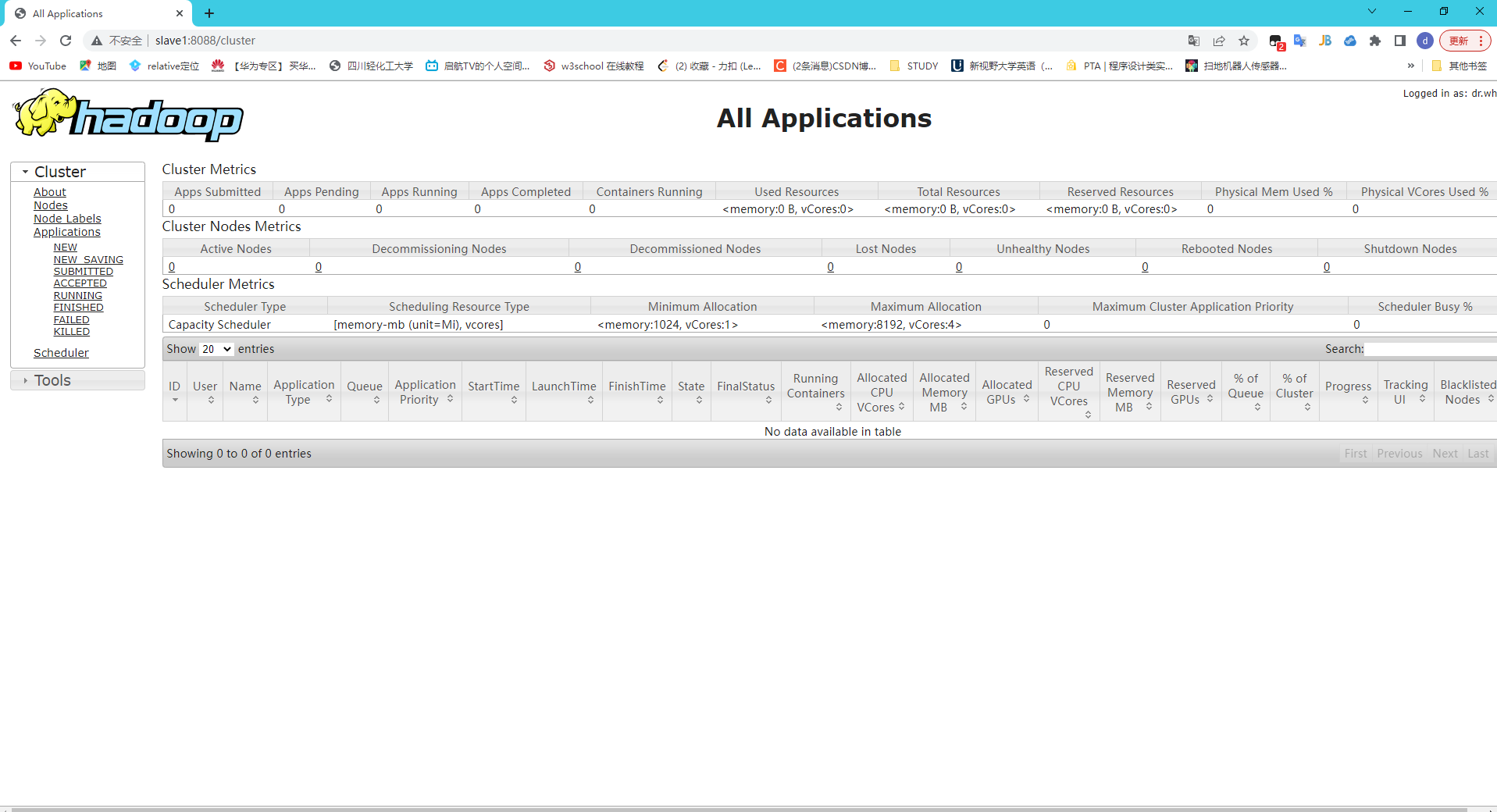
查看ui界面:
**注:**因为我在windows host文件添加了主机IP映射所以用Master:9870可以访问
hdfs ui:
yarn ui
集群关闭
1 | cd /usr/local/hadoop |
报错与处理办法
NameNode启动一段时间就挂掉了(hdfs过一段时间就不能访问了)
jps查看进程信息,发现NameNode没了,cd到/usr/local/hadoop/logs找到namenode的日志查看发下报错信息:
1 | ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: RECEIVED SIGNAL 15: SIGTERM |
有以下几种可能解决办法:
(1)
1 | cd /usr/local/hadoop |
(2)
关闭集群,做如下配置,然后重启hadoop:
1 | cd /usr/local/hadoop/etc/hadoop |
(3)
删除所有节点hadoop目录下的data和logs文件夹,重新进行格式化,启动集群。(没有办法的办法)不要轻易重新格式化因为这可能造成ID不一致,NameNode启动不了(到时候还得再重新格式化)。
(4) 被病毒程序占用系统资源
分析:经StackOverflow这是一个系统问题,并不是hadoop的错误,在hadoop运行过程中系统态cpu占用率太高被系统kill掉了,使用top命令查看cpu使用率一度到了96%,在关闭hadoop集群以后,top查看仍有hadoop用户的进程,并且cpu占用率还高达50%。这个进程kill掉后还会自启,并且pid还会改变。所以可以推断这是遭恶意攻击了。
原因:
可能是之前在用vpn看StackOverflow时,没关闭vpn的情况下直接用xshell连接过服务器导致ip暴露了
解决:
查询正在使用socket的此进程名的直接ip
1 | netstat -anp | grep zapppp # 通过top查看占用资源的进程COMMAND为zapppp |
经查,查询到的ip是国外的,禁掉ip
1 | iptables -A INPUT -p tcp -s 目标ip -j DROP |
程序进程停了一段时间又重启了,关掉pam后门:
1 | sudo yum reinstall pam |
还是要自启,关闭定时服务,删除进程对应的目录:
1 | crontab -e # 注释掉所有内容(每行前加一个#) |
目前暂时没有出现那个进程了,cpu占用率也基本是百分之零点几。
NameNode启动不了
Connection time out / Connection refused
关闭防火墙
1 | sudo systemctl stop firewalld |
启动时报错hadoop0: ERROR: Cannot set priority of datanode process 2518或者其他端口
开启云服务器全部端口
NameNode DataNodeID不一致failed to start namenode
所有节点删除hadoop目录的tmp,data和logs文件夹,重新格式化,启动集群。