hadoop整合spark框架
hadoop整合spark的安装与配置
书接上篇hadoop集群
由于服务器已经安装了hadoop集群,所以运行spark就用spark on yarn模式了,把资源调度交给yarn。
安装spark
将spark安装包上传到/usr/local/中
1 | cd /usr/local |
配置
修改/usr/local/hadoop/etc/hadoop/yarn-site.xml
1 | vim /usr/local/hadoop/etc/hadoop/yarn-site.xml |
1 | <property> |
修改spark配置文件
1 | cd /usr/local/spark |
上传jar包到hdfs文件系统
1 | cd /usr/local/spark |
运行测试
1 | cd /usr/local/spark |
打开yarn ui即可看到运行结果
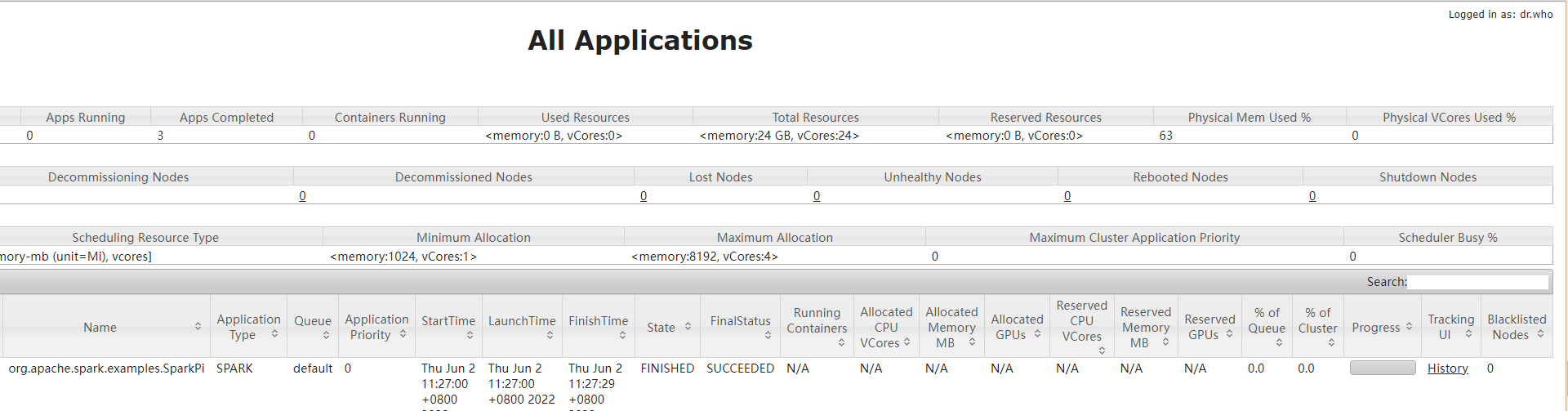
点开程序查看日志即可看到结果

常见问题总结
运行时一直上传文件,最后TimeOutException
运行examples的jar时一直上传依赖文件导致时间超时;把spark目录下的jars文件夹内所有jar包上传到hdfs文件系统即可。
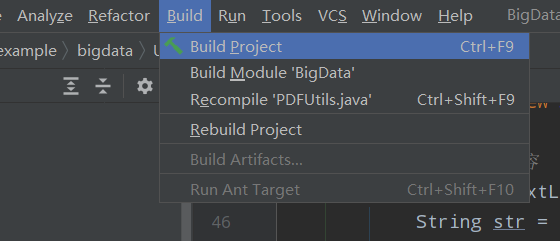
spark提交自己上传的jar包时,ClassNotFoundException
jar文件没有目标class文件;idea中将项目编译一下再用maven打包即可:
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles